Selected Working Papers
Large Language Model Hacking: Quantifying the Hidden Risks of Using LLMs for Text Annotation
Pre-print available at arXiv.
With Joahim Baumann, Paul Röttger , Aleksandra Urman, Flor Miriam Plaza-del-Arco, Johannes B. Gruber, and Dirk Hovy
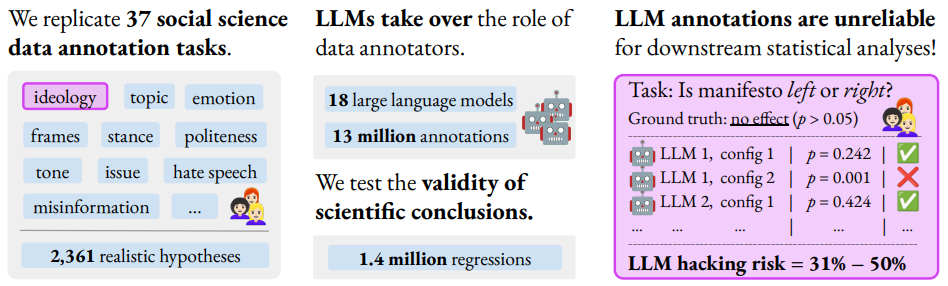
We quantify the risk of LLM hacking by replicating 37 data annotation tasks from 21 published social science research studies with 18 different models. Analyzing 13 million LLM labels, we test 2,361 realistic hypotheses to measure how plausible researcher choices affect statistical conclusions. We find incorrect conclusions based on LLM-annotated data in approximately one in three hypotheses for state-of-the-art (SOTA) models, and in half the hypotheses for small language models. While our findings show that higher task performance and better general model capabilities reduce LLM hacking risk, even highly accurate models do not completely eliminate it. The risk of LLM hacking decreases as effect sizes increase, indicating the need for more rigorous verification of findings near significance thresholds. Our extensive analysis of LLM hacking mitigation techniques emphasizes the importance of human annotations in reducing false positive findings and improving model selection. Surprisingly, common regression estimator correction techniques are largely ineffective in reducing LLM hacking risk, as they heavily trade off Type I vs. Type II errors.
Beyond accidental errors, we find that intentional LLM hacking is unacceptably simple. With few LLMs and just a handful of prompt paraphrases, anything can be presented as statistically significant. Overall, our findings advocate for a fundamental shift in LLM-assisted research practices, from viewing LLMs as convenient black-box annotators to seeing them as complex instruments that require rigorous validation. Based on our findings, we publish a list of practical recommendations to limit accidental and deliberate LLM hacking for various common tasks.
The Geographical Dimension of Group Based Appeals: Evidence from 50 Years of Swedish Parliamentary Speech
Revise and Resubmit, Political Geography